The situation we faced sounds like the beginning of a technical horror movie, in which the antagonist, instead of choosing suburban families as his victims, goes for databases. There was no indication of this, but in an instant, a key application handling our client’s sales started running so slowly that logging into it became impossible. 28 TB of the database became inaccessible. The entire production warehouse froze like a GTX 480 on which someone had just tried to run The Witcher III.
This is a story that any enterprise could have been affected by. It also highlights how suddenly and unexpectedly performance problems can hit a database, crippling key business operations. This case is a perfect example of how important it is not only to respond quickly to crises but more importantly – how to anticipate and prevent them.
*As a reputable provider of database solutions, we always approach each case with full awareness of responsibility. Therefore, protecting the privacy of our clients’ data is our top priority. Accordingly, all sensitive information has been anonymized. We did this to ensure the safety of our clients while allowing us to present this interesting case to a wider audience.
On The Way to Identify The Underlying Issue
The moment we realized that our client’s database had a problem that serious as to prevent them from continuing their business, bringing it back to the status quo became our top priority.
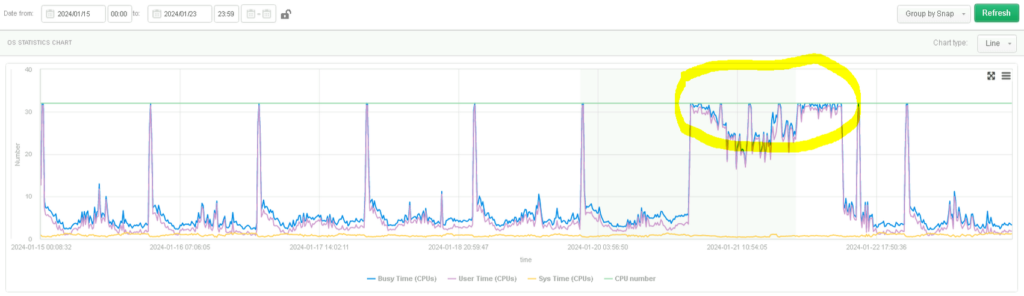
CPU load going up to 100%
At the very beginning, we set about trying to identify the source of the outage – the initial diagnosis of the problem carried out with our monitoring application allowed us to understand that at the critical moment, it was the CPU load that reached 100%. This is evident in the graph shown above, where we marked the area of failure in yellow.
One Problem, Different Views
On the IT team responsible for solving this problem, different members may have viewed the situation each in their own way:
- A database administrator might have seen this as a query optimization challenge. After all, it was possible that nothing but inefficient queries were taxing the system more than they should.
- An infrastructure specialist might have considered a direct answer to the problem in the form of increasing hardware resources. Why not increase CPU resources if they are the ones fully utilized?
- An application developer might have noted the need to review code for potential memory leaks or other inefficiencies that could lead to excessive CPU load.
- A business analyst might wonder if the sudden increase in CPU load is rooted in business-level changes or increased user traffic. This would require a detailed analysis of usage patterns.
In Truth, There Were Two Possibilities
There were two possibilities on the table: one that suggested solving the problem by increasing resources, which, with the enormity of 28 TB of data and 32 high-performance processors, meant a considerable expense. The other, more insightful, involved understanding the root of the problem.
The choice fell on the second path. The decision was neither easy nor quick, but the team agreed that it was only by understanding the root of the problem that we could come to a lasting solution. The goal was not only to remedy the current crisis but to also safeguard the system against similar challenges in the future. As it later turned out, this was the right decision – increasing CPU power, not only expensive, would not have resolved the issue, even partially.
In Search of the Cause of The Extraordinary CPU Load
We had already come to the conclusion that CPU saturation was the source of the problem. However, this was only the beginning of the journey. The next step was to understand what exactly was responsible for such high CPU usage. Analysis of the CPU time graphs allowed us to quickly narrow down the circle of suspects.
The red line represents the overall CPU time, while the yellow fill indicates the CPU time occupied by individual queries:
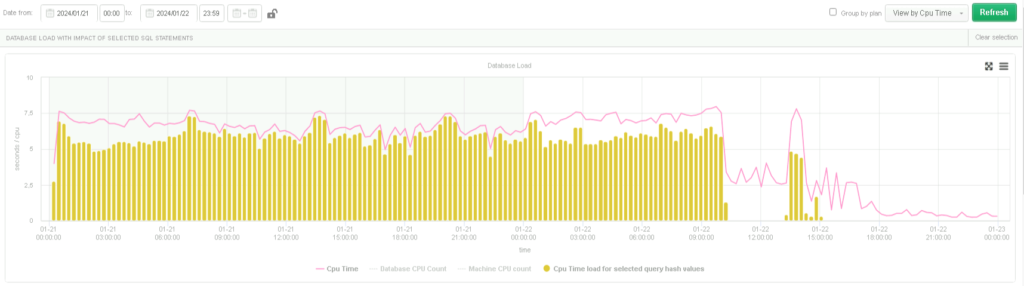
CPU time and CPU query time
Then, we identified a particular query that suddenly began to load the CPU extremely heavily.
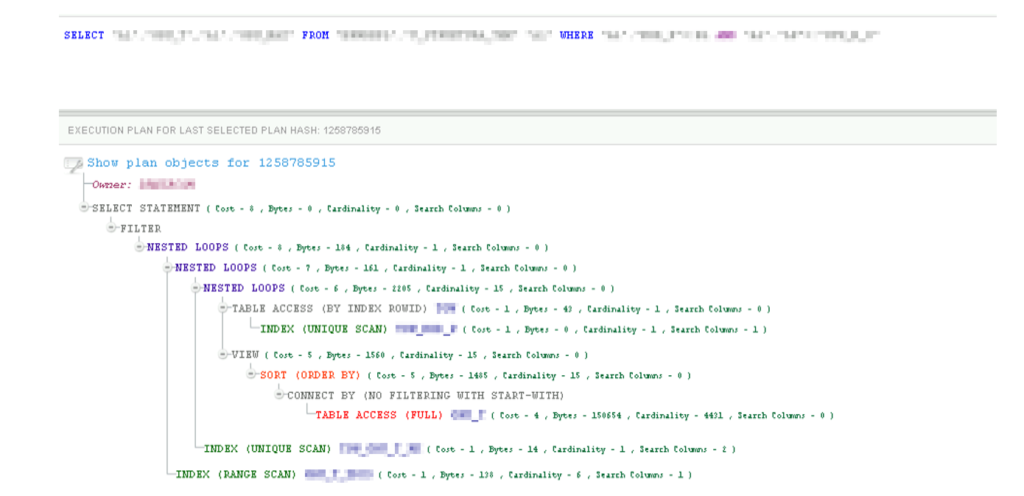
A query that saturated the CPU
Next, we posed a question: is this query new to the system, or was it present before, but on a much smaller scale? The answer came as a graph showing the number of runs of this query over January 2024. The data was shocking – on January 21 and 22 the number of executions of this query jumped from a daily 3.5 million to more than 100 million. Such an unexpected increase was an obvious source of performance failure:
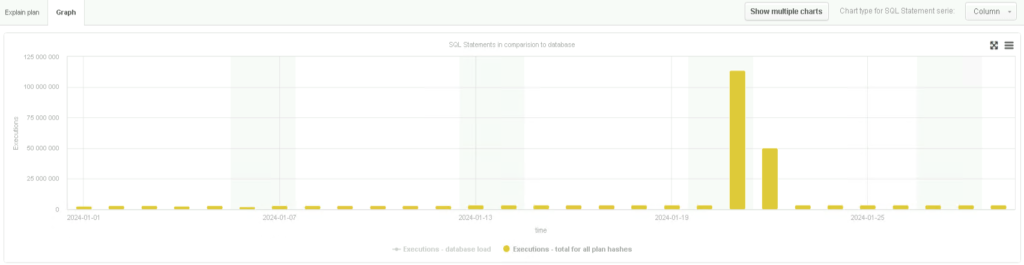
A graph showing the number of runs of the problematic query
Although the execution time per query was short (50 milliseconds), the cumulative number of runs led to a complete saturation of available CPU resources.
The Solution – Why Was the CPU Load so High?
Understanding the scale of the problem quickly directed our efforts beyond the limits of this database. It became clear that we wouldn’t find the solution in optimizing queries or increasing the computing power of the servers. Instead, it was necessary to turn to the application development team. We needed to understand what changes could have caused such a drastic increase in the number of queries.
The question we needed to ask was not only about the technical aspects of the change but also about the business case for it – it was obvious that such a sudden increase in activity could not be caused by a natural increase in market demand.
Conclusion
This, and many other experiences, underscore the importance of a holistic approach to technical problems. From the technical aspect to the infrastructure and the business implications, different perspectives within the IT team can contribute to a deeper understanding of the situation.
It is often tempting to solve problems by investing in hardware. After all, money for such expenses will almost always be possible to find. However, it’s worth remembering that this is often more like treating the symptoms than the disease itself. In such cases, increasing hardware resources is rarely the best solution.


