Obciążenie CPU, z którym przyszło nam się zetrzeć, brzmi jak początek technicznego horroru, w którym antagonista, zamiast wybierać na swoje ofiary rodziny z przedmieść, bierze na cel bazy danych. Nic na to nie wskazywało, ale w jednej chwili, kluczowa aplikacja obsługująca sprzedaż naszego klienta, zaczęła działać tak wolno, że logowanie do niej stało się niemożliwe. 28 TB bazy danych stało się niedostępne, a cały magazyn produkcyjny zamarł niczym GTX 480, na którym ktoś właśnie spróbował uruchomić Wiedźmina 3.
Podobna historia, mogła mieć miejsce w każdym przedsiębiorstwie. Jednocześnie podkleśla, jak nagle i nieoczekiwanie problemy z wydajnością mogą uderzyć w bazę danych, paraliżując kluczowe operacje biznesowe. Ten przypadek stanowi doskonały przykład na to, jak ważne jest nie tylko szybkie reagowanie na kryzysy, ale przede wszystkim ich przewidywanie i zapobieganie im.
*Jako renomowany dostawca rozwiązań bazodanowych zawsze podchodzimy do każdego przypadku z pełną świadomością odpowiedzialności. Ochrona prywatności danych naszych klientów jest dla nas priorytetem. W zwiążku z tym, wszelkie wrażliwe informacje zostały zanonimizowane, po to aby zapewnić bezpieczeństwo naszych klientów, jednocześnie pozwalając nam na przedstawienie tego ciekawego przypadku szerszemu gronu profesjonalistów.
Identyfikacja Problemu
W momencie, w którym zorientowaliśmy się, że baza danych naszego klienta ma tak poważny problem, że uniemożliwia im to prowadzenia dalszej działalności, doprowadzenie do statusu quo stało się dla nas najwyższym priorytetem.
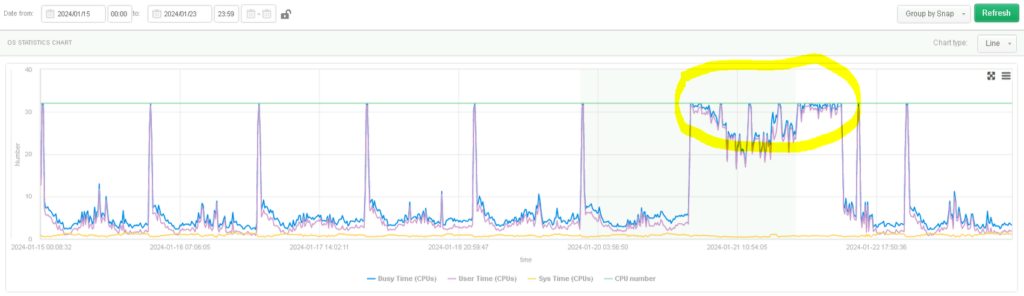
Obciążenie CPU w 100%
Na samym początku zajęliśmy się próbą zidentykowania źródła przestoju. Wstępna diagnoza problemu przeprowadzona za pomocą naszej aplikacji do monitoringu pozwoliła nam zrozumieć, że krytycznym momencie to właśnie zasób CPU był wykorzystywany w 100%. Jest to widoczne na przedstawionym wyżej wykresie, gdzie obszar awarii zaznaczony jest kolorem żółtym.
Jeden problem różne spojrzenia
W zespole IT odpowiedzialnym za rozwiązanie tego problemu, różni członkowie mogli postrzegać sytuację w odmienny sposób:
- Administrator bazy danych mógł zobaczyć w tym wyzwanie dotyczące optymalizacji zapytań. Możliwe było przecież to, że nic innego niż nieefektywne zapytania obciążały system bardziej, niż powinny.
- Specjalista od infrastruktury mógłby rozważać bezpośrednią odpowiedź na problem w postaci zwiększenia zasobów sprzętowych. Dlaczego by nie zwiększyć zasobów CPU jeżli to właśnie one są w pełni wykorzystywane?
- Deweloper aplikacji mógł zauważyć potrzebę przeglądu kodu pod kątem potencjalnych wycieków pamięci lub innego rodzaju niewydajności. Te mogłyby prowadzić do nadmiernego obciążenia procesorów.
- Analityk biznesowy mógłby zastanawiać się, czy nagłe zwiększenie obciążenia CPU ma swoje źródło w zmianach na poziomie biznesowym lub wzmożonym ruchu użytkowników. To z kolei, wymagałoby szczegółowej analizy wzorców użytkowania.
Tak na prawdę, były dwie możliwości
Na stole leżały wiec dwie możliwości. Pierwsza sugerowała rozwiązanie problemu przez zwiększenie zasobów. Przy ogromie 28 TB danych i 32 wysokowydajnych procesorach oznaczało to niebagatelne wydatki. Druga, bardziej wnikliwa, zakładała zrozumienie korzeni problemu.
Wybór padł na drugą ścieżkę. Nie była to decyzja łatwa, ale zespół zgodził się, że jedynie przez zrozumienie sedna problemu, można będzie znaleźć trwałe rozwiązanie. Takie, które nie tylko zaradzi bieżącemu kryzysowi, ale również zabezpieczy system przed podobnymi wyzwaniami w przyszłości. Jak się później okazało była to słuszna decyzja – zwiększenie mocy CPU, nie dość, że kosztowne, nie spowodowałoby nawet częściowego rozwiązania problemu.
W poszukiwaniu przyczyny
Doszliśmy już do wniosku, że to właśnie wysycenie CPU było źródłem problemu, był to jednak dopiero początek drogi. Kolejnym etapem było zrozumienie, co dokładnie odpowiada za tak wysokie zużycie procesora. Analiza wykresów CPU time pozwoliła szybko zawęzić krąg podejrzanych.
Czerwona linia reprezentuje ogólny czas pracy CPU, a żółte wypełnienie wskazuje na czas pracy CPU zajęty przez jedno zapytanie:
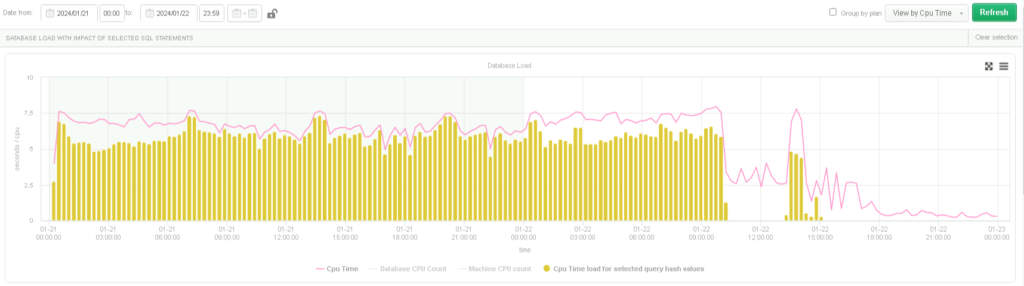
CPU time i CPU time zapytania
Następnie zidentyfikowaliśmy konkretną kwerendę, która nagle zaczęła obciążać CPU w sposób niezwykle intensywny.
Zapytanie, które wysyciło CPU
Postawione więc zostało pytanie: czy zapytanie, które spowodowało obciążenie CPU jest nowością w systemie, czy może było obecne wcześniej, ale na znacznie mniejszą skalę? Odpowiedź przyniósł wykres przedstawiający liczbę uruchomień tego zapytania na przestrzeni stycznia 2024 roku. Dane były szokujące – w dniach 21 i 22 stycznia liczba wykonania tego zapytania skoczyła z codziennych 3,5 miliona do ponad 100 milionów. Taki niespodziewany wzrost był oczywistym źródłem awarii wydajności:
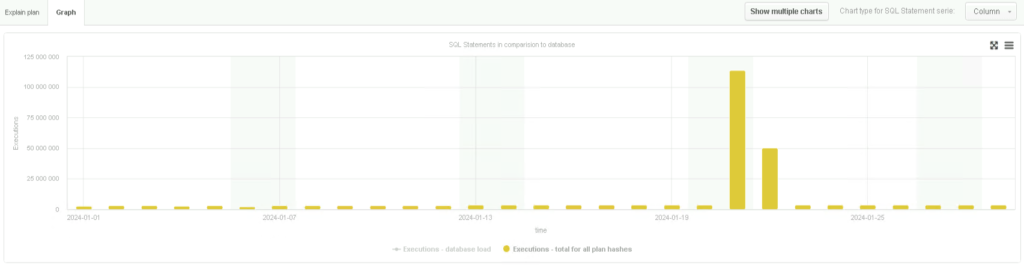
Wykres przedstawiający liczbę uruchomień problematycznego zapytania
Rozwiązanie
Zrozumienie skali problemu szybko skierowało nasze działania poza granice tej bazy danych. Stało się jasne, że rozwiązanie nie znajdzie się w optymalizacji zapytań ani w zwiększeniu mocy obliczeniowej serwerów. Zamiast tego, konieczne było zwrócenie się w stronę zespołu odpowiedzialnego za rozwój aplikacji, musieliśmy zrozumieć, jakie zmiany mogły spowodować tak drastyczny wzrost liczby uruchomień zapytania. Pytanie, które należało zadać, dotyczyło nie tylko technicznych aspektów zmiany, ale także jej uzasadnienia biznesowego – było oczywiste, że tak nagły wzrost aktywności nie mógł wynikać z naturalnego wzrostu zapotrzebowania rynkowego.
Podsumowując
To, i wiele innych doświadczeń, podkreśla wagę holistycznego podejścia do problemów technicznych. Od technicznego aspektu, przez infrastrukturę, po biznesowe implikacje – różne perspektywy w zespole IT mogą przyczynić się do głębszego zrozumienia sytuacji.
Często kusi nas, żeby rozwiązywać problemy inwestując w hardware – pieniądze na takie wydatki znajdą się przecież prawie zawsze. Warto jednak pamiętać, że często przypomina to bardziej leczenie symptomów niż samej choroby, a zwiększenie zasobów sprzętowych rzadko jest najlepszym rozwiązaniem.


