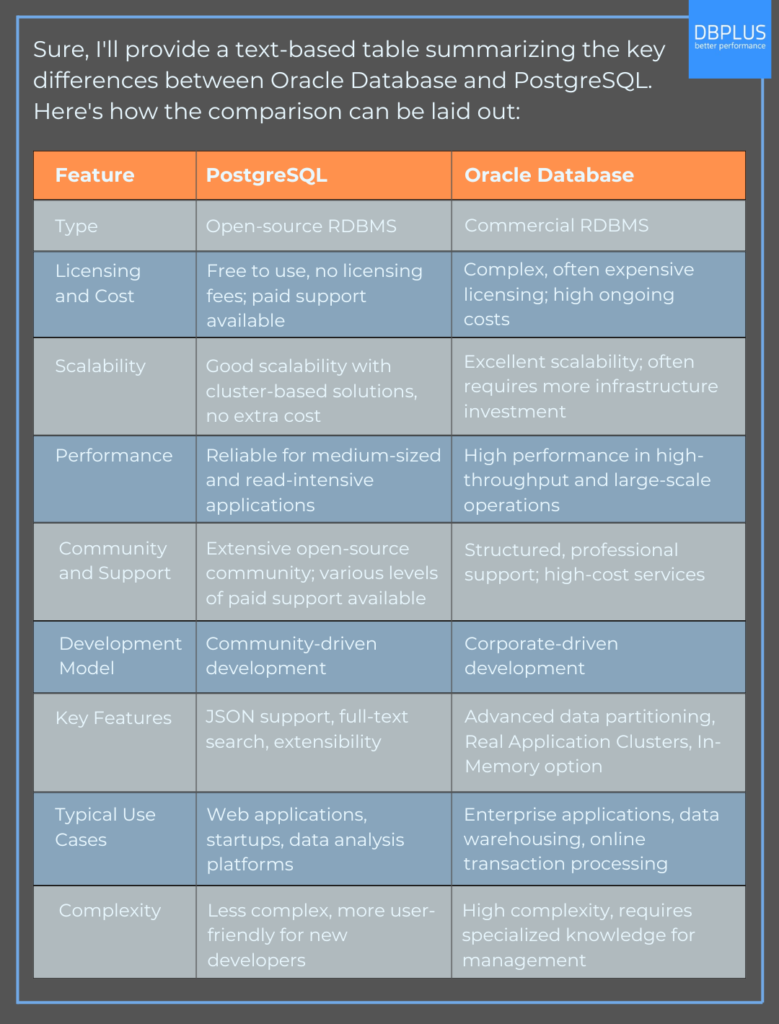
PostgreSQL vs Oracle – platforma open-source, która promuje adaptacyjność i dostępność vs zastrzeżony system zaprojektowany z myślą o wysokiej przepustowości i skalowalności w środowiskach korporacyjnych. Te systemy baz danych, choć oba zaprojektowane do zarządzania ogromnymi ilościami danych, różnią się znacznie pod względem podejścia, filozofii i targetu.
PostgreSQL to oparty na społeczności, elastyczny model, który wspiera dostosowywanie i innowacje. Jest idealny dla podmiotów, które cenią sobie elastyczne i opłacalne rozwiązania. Oracle, z kolei, celuje w operacje na dużą skalę, a może to robić dzięki swojej nastawionej na wydajność architekturze, która zapewnia niezawodność i solidność przy dużych obciążeniach.
Przegląd PostgreSQL

PostgreSQL wywodzi się z akademickiej kolebki Uniwersytetu Kalifornijskiego w Berkeley. Wnosi ze sobą dziedzictwo przesiąknięte tradycją rygorystycznej zgodności z językiem SQL i łatwości adaptacji. Dzięki tym cechom zdobył serca purystów i pragmatyków w świecie baz danych. Ten obiektowo-relacyjny system zarządzania bazami danych o otwartym kodzie źródłowym jest elastyczny, niezawodny i niezwykle demokratyczny w swojej dostępności.
Kluczowe cechy
- Elastyczność: PostgreSQL na nowo definiuje elastyczność, umożliwiając użytkownikom tworzenie i integrowanie niestandardowych typów danych i funkcji bezpośrednio w bazie danych. W ten sposób zaspokaja specyficzne wymagania różnych aplikacji.
- Zgodność z ACID: System zapewnia, że każda transakcja jest przetwarzana z żelazną gwarancją precyzji i integralności. W ten sposób wzmacnia fundamentalną stabilność bazy danych.
- Wbudowana replikacja: Postgres zobowiązuje się do ciągłej dostępności danych, chroniąc przed zakłóceniami spowodowanymi awariami serwerów lub katastrofami dzięki solidnym protokołom replikacji.
- Obsługa JSON: PostgreSQL zręcznie obsługuje dane JSON, przekształcając chaotyczne, częściowo ustrukturyzowane dane w uporządkowane, gotowe do zapytań informacje.
- Wyszukiwanie pełno-tekstowe: Ta funkcja jest daleka od podstawowego narzędzia. Umożliwia ona użytkownikom wydajne przeszukiwanie obszernych danych tekstowych, precyzyjnie wyodrębniając istotne informacje.
Popularne zastosowania
Ten system bazodanowy znajduje zastosowanie w wielu aplikacjach – od zasilania złożonych aplikacji internetowych po zaawansowane platformy do analizy danych. Jego zasięg obejmuje zarówno raczkujące startupy, jak i średnie przedsiębiorstwa o już ugruntowanej pozycji na rynku. Każda z firm będzie w stanie docenić wydajność Postgresu bez ponoszenia wysokich kosztów. Wybór ten odzwierciedla zaangażowanie w filozofię, która ceni otwartość, trwałość i zdolność adaptacji. Jest to system baz danych, który oprócz przechowywania i pobierania danych, ewoluuje wraz z użytkownikami.
Przegląd bazy danych Oracle

Baza danych Oracle po raz pierwszy rozwinęła swoje cyfrowe wici w 1977 roku za sprawą Lawrence’a Ellisona. Ten komercyjny system zarządzania relacyjnymi bazami danych od początku był przeznaczony do czegoś większego. Jego zadaniem było sprostanie ciężkim wymaganiom dużych operacji korporacyjnych. Już od samego początku Oracle wpisał się w płaszczyznę rozwiązań bazodanowych jako synonim wysokiej wydajności i nieograniczonej skalowalności. Stało się tak głównie dzięki zręcznemu radzeniu sobie z niezliczonymi zawiłościami danych w rozległych ekosystemach korporacyjnych.
Kluczowe cechy
- Skalowalność: Oracle wykracza poza zwykłą funkcjonalność i wkracza w sferę absolutnej konieczności. Rozwija się pod ciężarem wymagań na poziomie korporacyjnym, zapewniając, że wraz z rozwojem firm, ich bazy danych nie są ograniczone do radzenia sobie z nimi.
- Wysoka dostępność: Oracle Real Application Clusters (RAC) i Data Guard chronią bazę przed przestojami i utratą danych. Funkcje te w mniejszym stopniu odnoszą się do „jeśli”, a w większym do „kiedy” – zapewniając ciągłość i płynność działania w świecie, w którym dane nie zatrzymują się dla nikogo.
- Zaawansowane zabezpieczenia: Naruszenia danych są tak powszechne jak i niebezpieczne, a Oracle wzmacnia swoje mury dzięki precyzyjnej kontroli dostępu i żelaznym środkom szyfrowania. Nie chodzi tu o przechowywanie danych, a bardziej o zapobieganie zagrożeniom, tworząc fortecę w środowisku pełnym cyberprzestępców.
- In-Memory: Opcja Oracle In-Memory skraca czas odpowiedzi na zapytania i pozwala drastycznie zaoszczędzić wiele milisekund na każdej interakcji z bazą danych.
- Partycjonowanie: Oracle traktuje dane nie jako jezioro, ale raczej jako serię mniejszych, nadających się do żeglugi stawów. Partycjonowanie w Oracle polega na zapewnieniu natychmiastowego dostępu do danych, usprawnieniu wyszukiwania i precyzyjnym zwiększeniu wydajności pamięci masowej.
Popularne zastosowania
Oracle kładzie cyfrowe podwaliny pod gigantyczne magazyny danych i platformy przetwarzania transakcji online, gdzie szybkość, dokładność i niezawodność to podstawa. W ściśle regulowanych korytarzach Oracle dominuje, zapewniając szkielet niezbędny do operacji, które nie mogą sobie pozwolić na odrobinę błędu lub opóźnienia.
Funkcjonalność: PostgreSQL vs Oracle
Funkcjonalność systemu baz danych najczęściej decyduje o jego przydatności do określonych zadań lub środowisk. Zrozumienie funkcjonalności oferowanej przez PostgreSQL i Oracle ujawnia różne ścieżki, które każdy z nich obiera, aby służyć swoim bazom użytkowników.
PostgreSQL
PostgreSQL wyróżnia się rozbudowanymi opcjami indeksowania, które odgrywają kluczową rolę w optymalizacji wydajności bazy danych poprzez szybsze wyszukiwanie rekordów. Wspomniane możliwości indeksowania są uzupełniane przez natywne interfejsy programistyczne, które zachęcają do dostosowywania i elastyczności. Deweloperzy uważają, że PostgreSQL jest atrakcyjny, ponieważ pozwala na dostosowane podejście, umożliwiając im dostosowanie bazy danych do złożonych i bardziej zróżnicowanych wymagań aplikacji. Ta zdolność adaptacji sprawia, że PostgreSQL jest szczególnie przydatny w środowiskach, w których innowacje i dostosowywanie są w ciągłym ruchu.
Oracle
Z drugiej strony spektrum mamy Oracle, zaprojektowane do obsługi środowisk o dużej objętości i dużej liczbie transakcji z niezrównaną sprawnością. Jego możliwości przetwarzania transakcji zapewniają, że duże przedsiębiorstwa mogą bez wahania polegać na Oracle w zakresie krytycznych operacji. Jednak szeroka funkcjonalność ma swoją cenę, dosłownie, jak i w przenośni, ponieważ funkcje te są często zablokowane za wyższymi opłatami licencyjnymi. Mimo to wielu twierdzi, że koszt ten jest uzasadniony zdolnością Oracle do dostarczania wysokowydajnego i niezawodnego przetwarzania transakcji na dużą skalę.
Skalowalność: PostgreSQL vs Oracle
Skalowalność bazy danych określa jej zdolność do sprawnego radzenia sobie ze wzrostem – nie tylko pod względem ilości danych, ale także złożoności i współbieżności operacji. Jest to również miejsce, w którym ścieżki Postgres i Oracle najbardziej się rozchodzą.
PostgreSQL
Skalowalność Postgresu jest ściśle związana z jego architekturą. Jego charakter open-source umożliwia użytkownikom sprawdzanie, modyfikowanie i ulepszanie kodu źródłowego w celu dostosowania go do konkretnych potrzeb. W tym przypadku skalowalność nie wiąże się ze zwiększonymi opłatami licencyjnymi.
PostgreSQL wykorzystuje partycjonowanie tabel i obsługuje wiele technik indeksowania, w tym uogólnione drzewa wyszukiwania (GiST), uogólnione odwrócone indeksy (GIN) i indeksy zakresu bloków (BRIN). Te opcje indeksowania są szczególnie korzystne w przypadku aplikacji z dużymi zbiorami danych, które wymagają wydajnych zapytań w czasie. Ponadto podejście PostgreSQL do obsługi połączeń, z chwaloną obsługą puli połączeń, zapewnia, że może zarządzać rosnącą liczbą jednoczesnych żądań użytkowników bez odpowiadającego im liniowego wzrostu zużycia zasobów.
Oracle
Tymczasem, Oracle został zbudowany z myślą o skalowalności klasy korporacyjnej.
RAC umożliwia wielu instancjom baz danych Oracle dostęp do jednej bazy danych, zapewniając odporność na błędy, wysoką dostępność i wysoki stopień skalowalności. Idąc dalej, mamy zaawansowane funkcje partycjonowania Oracle. Partycjonowanie list, partycjonowanie zakresów i partycjonowanie hash mogą znacznie poprawić wydajność i łatwość zarządzania w środowiskach o dużej skali. Łącząc te możliwości partycjonowania z potężną infrastrukturą gridową Oracle, otrzymujemy bazę danych, która może obsłużyć ogromny wzrost ilości danych i obciążenia użytkowników przy minimalnym wpływie na wydajność.
Podejście Oracle zakłada jednak dostęp do znacznych nakładów na infrastrukturę. Skalowalność, którą oferuje, jest ekspansywna, ale wymaga głębokiej integracji technologii Oracle oraz znacznych początkowych i bieżących inwestycji; inwesycji zarówno w sprzęt, jak i specjalistyczną wiedzę. To sprawia, że Oracle jest doskonałym wyborem dla dużych przedsiębiorstw, które potrzebują gwarantowanej wydajności przy dużych obciążeniach. Może być jednak stromym wzgórzem do pokonania dla organizacji bez tego samego poziomu zasobów.
Wydajność: PostgreSQL vs Oracle
W dialogu między Postgres i Oracle dyskurs na temat wydajności to opowieść o dwóch filozofiach i dwóch różnych strategiach. W końcu wydajność to nie tylko szybkość, ale także sposób, w jaki przekłada się ona na niezawodność i efektywność.
PostgreSQL
Postgres jest szczególnie użyteczny w przypadku średnich baz danych, w których operacje są intensywnie odczytywane. Tutaj działa z niezawodnością, która jest zarówno przewidywalna, jak i subtelna – silnik działa cicho, ale stabilnie, w tle. Każde zapytanie, bez względu na to, jak skomplikowane, spotyka się ze stałym czasem odpowiedzi.
Tam, gdzie nacisk kładziony jest zarówno na stabilność i niezawodność, jak i na samą szybkość, inteligentny planer zapytań Postgres optymalizuje zapytania przy użyciu zaawansowanych algorytmów i statystycznej analizy danych. Właśnie to poprawia wydajność w tych systemach, w których wydajne odczytywanie danych jest bardziej krytyczne niż szybkie zapisywanie danych.
Oracle
Dla kontrastu, Oracle preferuje środowiska operacyjne o wysokiej przepustowości i dużej skali. Wydajność tej bazy danych została zaprojektowana z myślą o dużych obciążeniach wymaganych w ogromnych przedsiębiorstwach, w których operacje na bazach danych są CAŁOŚCIĄ działalności, a nie tylko jej częścią.
Oracle został zaprojektowany w celu maksymalizacji wydajności i minimalizacji opóźnień. Mówimy tutaj o funkach takich jak zaawansowane buforowanie wyników, zaawansowane partycjonowanie i przetwarzanie danych w pamięci, . Zdolność Oracle do rozmieszczania danych na wielu serwerach i optymalizacja zarówno operacji odczytu, jak i zapisu pozwalają mu świetnie radzić sobie w wymagających scenariuszach.
Bezpieczeństwo: PostgreSQL vs Oracle
Jeśli chodzi o bezpieczeństwo, PostgreSQL i Oracle wdrażają różne, ale potężne arsenały.
PostgreSQL
PostgreSQL podchodzi do bezpieczeństwa z prostotą, która nie przeczy jego skuteczności. Oferuje szyfrowanie SSL, tworząc bezpieczny tunel do transmisji danych i zapewniając, że dane w ruchu pozostają niewidoczne dla wścibskich oczu. Poza szyfrowaniem, PostgreSQL wykorzystuje kontrolę dostępu opartą na rolach, strategię, która oprócz dyktowania, kto może uzyskać dostęp do bazy danych, określa, w jaki sposób i kiedy może to zrobić. Jest to bardziej kontrola oparta na rolach, narracja bezpieczeństwa, która jest zgodna z etosem operacyjnym organizacji i potrzebami zgodności.
Oracle
Z drugiej strony Oracle prezentuje paradygmat bezpieczeństwa, który jest bardziej wyczerpujący i ekspansywny. Ten pakiet zabezpieczeń obejmuje zaawansowane opcje szyfrowania, które chronią dane w spoczynku i w ruchu, a także zaawansowane funkcje audytu. Te uważnie śledzą dostęp do danych i ich wykorzystanie.
Ramy bezpieczeństwa Oracle są wielowarstwowe i obejmują takie funkcje, jak wirtualna prywatna baza danych (VPD) i drobnoziarnisty audyt. Połączenie tych funkcji pozwala na precyzyjną kontrolę i monitorowanie dostępu do danych, dostosowane dokładnie do potrzeb dużych organizacji i zgodności z przepisami.
Licencjonowanie i koszty: PostgreSQL vs Oracle
W tym przypadku, rozróżnienia odnoszą się bezpośrednio do intencji i ekosystemów otaczających każdy system baz danych, ujawniając wiele na temat tego, komu każdy z nich ma służyć.
PostgreSQL
PostgreSQL przyjmuje model dostępności finansowej i operacyjnej, który jest prawie tak otwarty, jak jego kod źródłowy. Podstawowa część PostgreSQL jest darmowa, co stanowi zaproszenie dla małych i dużych przedsiębiorstw do budowania, rozbudowywania i dostosowywania systemu bez konieczności ponoszenia początkowych lub cyklicznych opłat licencyjnych.
Ta filozofia otwartego dostępu znacznie obniża całkowity koszt posiadania, umieszczając PostgreSQL w zasięgu każdego, kto ma chęć po niego sięgnąć. Chociaż PostgreSQL jest darmowy, oferuje również opcjonalne płatne wsparcie, zapewniając możliwość rozszerzonej pomocy, z której firmy mogą korzystać w razie potrzeby, bez obowiązkowych długoterminowych zobowiązań finansowych. Ta demokratyzacja dostosowuje koszty do wzrostu, dzięki czemu PostgreSQL jest opłacalną opcją zarówno dla startupów, jak i firm o ugruntowanej pozycji.
Oracle
Oracle jest natomiast często postrzegany przez pryzmat złożoności fiskalnej i struktur kosztowych, które mogą powodować bezsenność u niejednego przedsiębiorcy. Dla niewtajemniczonych (czyli większości śmiertelników), model licencjonowania stosowany przez Oracle może wydawać się zawiły i skomplikowany, poplątany i pokrętny.
Podejście Oracle do licencjonowania, żartobliwie nazywanego ” rogue vendor”, ma na celu wyciągnięcie maksymalnych przychodów z głębokich kieszeni dużych organizacji, które mogą sobie pozwolić na wysoką cenę wejścia i bieżące koszty. Model ten zapewnia, że zaawansowane możliwości Oracle są wspierane przez strumień przychodów, który wspiera szeroko zakrojone badania i rozwój, aczkolwiek kosztem szerszej dostępności.
W przypadku dużych przedsiębiorstw inwestycja w Oracle może być uzasadniona potrzebą wysokowydajnego, wysoce bezpiecznego i niezawodnego systemu baz danych, który działa w skali, której niewiele innych systemów może dorównać.
Społeczność i wsparcie: PostgreSQL vs Oracle
Społeczność i wsparcie mogą być często ostatnimi rzeczami, które bierzemy pod uwagę w przypadku baz danych, ale to właśnie one mają wpływ na czas rozwiązywania problemów. Postgres i Oracle są przykładem dwóch kontrastujących podejść do społeczności i systemów wsparcia.
PostgreSQL
PostgreSQL jest głównie napędzany przez społeczność. Społeczność open-source jest szeroka, żywa i pełna pasji. To sprawia, że bezpłatna pomoc jest dostępna za pośrednictwem forów, szczegółowej dokumentacji i rozległej sieci doświadczonych użytkowników, którzy przyczyniają się do rosnącego repozytorium wiedzy i narzędzi.
Taki model wsparcia demokratyzuje naukę i rozwiązywanie problemów, pozwalając użytkownikom na szukanie pomocy i dzielenie się rozwiązaniami w środowisku opartym na współpracy. Przejrzystość i wspólne dzielenie się wiedzą zwiększają poczucie przynależności i wkładu wśród użytkowników PostgreSQL.
Co więcej, dla osób wymagających bardziej ustrukturyzowanego systemu wsparcia dostępne są płatne opcje. Oferują one profesjonalną pomoc, ale są zbudowane na tym samym fundamencie wiedzy i zaangażowania społeczności.
Oracle
Podejście Oracle do usług wsparcia ma swoją cenę, która odzwierciedla jego korporacyjne podstawy. Chociaż Oracle zapewnia wsparcie, usługi te są drogie i nieraz dalekie od perfekcji,. Jest to pomoc bardziej transakcyjna niż komunalna.
Ustrukturyzowane, profesjonalne i szeroko zakrojone – wsparcie Oracle obejmuje jednak wszystko, od rozwiązywania problemów po proaktywne narzędzia zarządzania. Celem tego projektu jest zapewnienie integralności i wydajności bazy danych dla krytycznych operacji przedsiębiorstwa. Ten poziom wsparcia wiąże się jednak ze znacznymi kosztami, co może stanowić barierę dla mniejszych podmiotów lub tych o mniej krytycznych potrzebach w zakresie wsparcia.
Replikacja danych i wysoka dostępność: PostgreSQL vs Oracle
Bliźniacze koncepcje replikacji danych i wysokiej dostępności to gwarancje, które zapewniają nieprzerwane bicie serca operacji przedsiębiorstwa, nawet pod presją. Obie bazy danych zaspokajają te potrzeby, choć ich podejścia i implementacje odzwierciedlają różne filozofie operacyjne i ramy technologiczne.
PostgreSQL
PostgreSQL obsługuje replikację danych poprzez podwójne podejście: replikację strumieniową i replikację logiczną.
Replikacja strumieniowa w PostgreSQL pozwala na kopiowanie danych w czasie rzeczywistym z serwera podstawowego na jeden lub więcej serwerów pomocniczych. Ten typ replikacji jest fizyczny, bajt po bajcie, z lustrzanym odbiciem bazy danych o wysokiej wierności, które może przejąć niemal natychmiast, w przypadku awarii serwera podstawowego.
Replikacja logiczna, nieco bardziej elastyczne podejście, replikuje dane na poziomie indywidualnych zmian lub transakcji. Metoda ta pozwala na selektywną replikację, która może być kierowana do różnych baz danych lub wykorzystywana do zadań takich jak konsolidacja baz danych lub aktualizacja systemów bez przestojów.
Oracle
Oracle wykorzystuje cały zestaw funkcji mających na celu zapewnienie redundancji danych i ciągłości operacyjnej. Najważniejsze z nich to Oracle Data Guard i Real Application Clusters (RAC).
Zadaniem Data Guard jest replikacja danych, ale nie przed utworzeniem i zarządzaniem wieloma zapasowymi bazami danych. Te, są gotowe do przejęcia kontroli w każdej chwili. Nawet podczas nieoczekiwanych awarii, dostępność danych i ciągłość transakcyjna są utrzymywane bez zakłóceń.
Jako uzupełnienie Data Guard, Oracle wdraża Real Application Clusters (RAC), które podnoszą koncepcję wysokiej dostępności na nowy poziom. RAC umożliwia istnienie wielu instancji bazy danych Oracle, a co więcej, aktywną współpracę na wielu maszynach. Współpraca ta tworzy dynamiczny system.System, w którym równoważenie obciążenia i skalowalność są obsługiwane z taką finezją, że użytkownik może nawet nie wiedzieć, że wystąpił potencjalny problem.