Sytuacja początkowa
Korzystając z oprogramowania DBPLUS PERFORMANCE MONITOR przyjrzyjmy się czasowi ładowania 20 kwietnia. Od razu zauważamy, że podczas gdy czas ładowania zapytania zwykle waha się między 12 a 15 sekund na snapshot, w niektórych okresach występuje znaczny skok do ponad 2000 sekund.
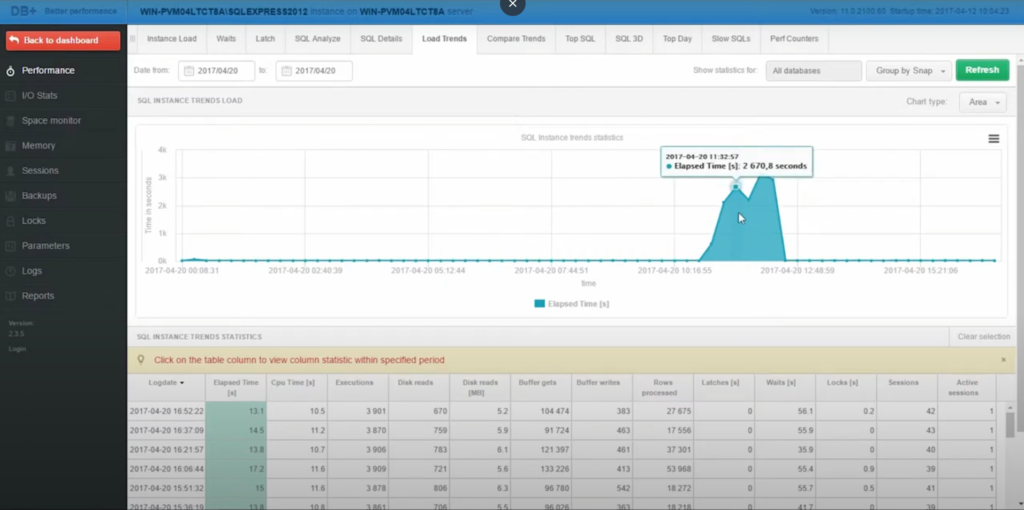
Taka anomalia może mieć poważny wpływ na ogólną wydajność bazy danych. Wydłużony czas przetwarzania zapytań sugerował, że system wskazywał na głębszy, prawdopodobnie systemowy problem. To wstępne odkrycie wymagało bardziej szczegółowego zbadania przyczyn tych opóźnień, prowadząc proces rozwiązywania problemów w kierunku określonych wąskich gardeł wydajności.
Na drodze do identyfikacji problemu
Po zidentyfikowaniu anomalii przy korzystaniu z oprogramowania DBPLUS PERFORMANCE MONITOR, kolejnym logicznym krokiem było poszukiwanie możliwej korelacji blokad z wykonaniami, odczytami z dysku, zapisami bufora itp. Jednak dopiero po przeanalizowaniu statystyk blokad, wzór stał się jasny – doszło do znacznego nakładania się momentów, w których czas trwania zapytań wzrasta i kiedy nasilają się problemy z blokadami.
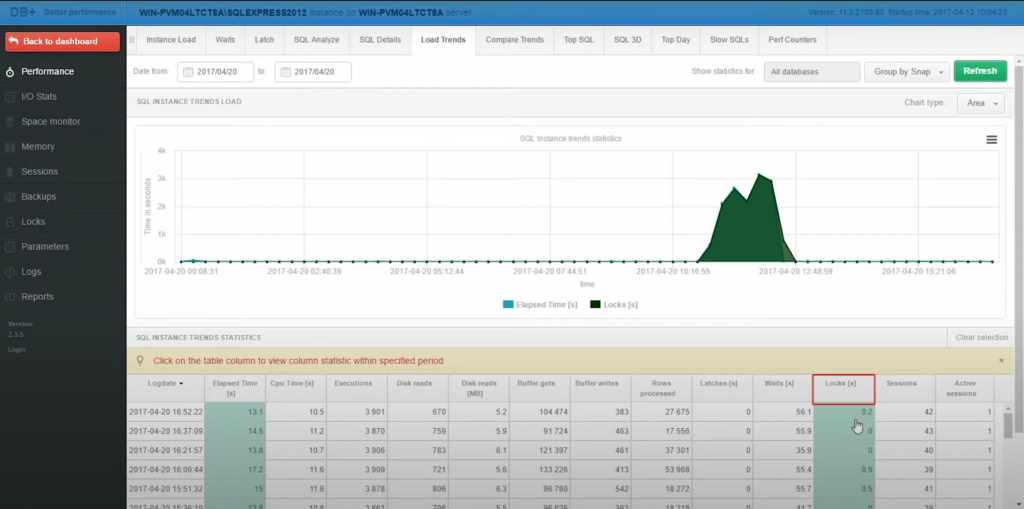
Szczegółowa analiza blokady
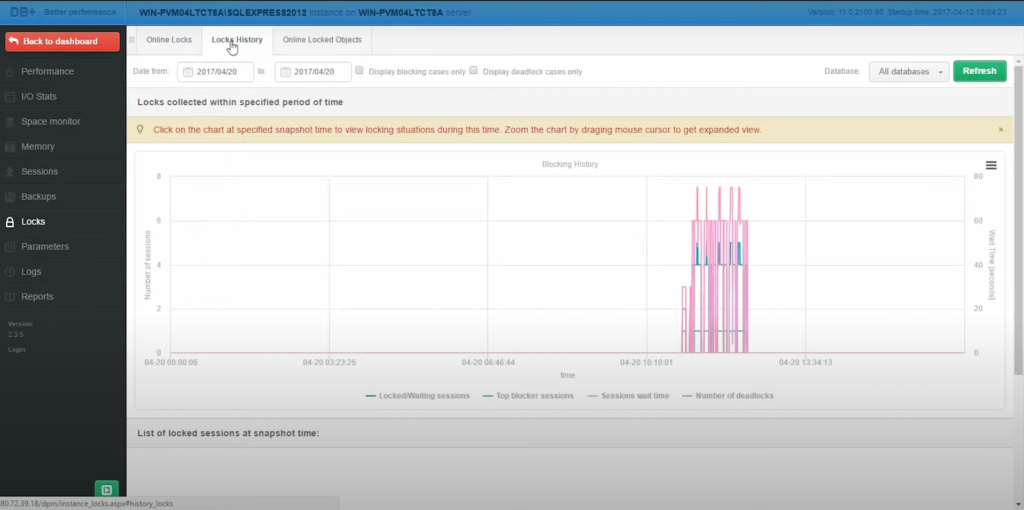
Aby rozpocząć dokładną analizę, przechodzimy do zakładki lock history, która rejestruje wszystkie zdarzenia blokad w danym dniu. Sekcja ta ma za zadanie przedstawić nam chronologię zdarzeń. Klikamy na poszczególne punkty na osi czasu, aby uzyskać dostęp do kompleksowych danych na temat każdego zdarzenia blokady.
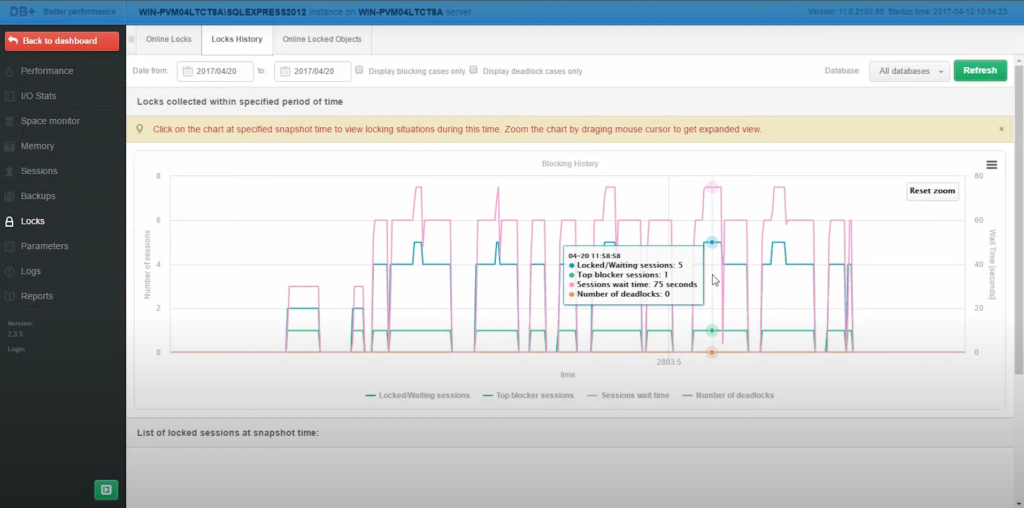
Jak przeprowadzimy analizę blokady:
- Dostęp do szczegółowych informacji: Wybierając określony punkt na osi czasu, otrzymujemy więcej szczegółów dotyczących każdego zdarzenia blokady. Obejmuje to czas wystąpienia blokady, czas jej trwania i określone elementy bazy danych, na które miała wpływ.
- Analiza sesji zablokowanych i oczekujących: Najważniejsze są nie tylko sesje, które aktywnie utrzymują blokady, ale także te, które są w stanie oczekiwania z powodu tych blokad. Dla każdej sesji wyświetlane są krytyczne dane, takie jak identyfikator sesji, status (aktywna, oczekująca, uśpiona) oraz dokładny czas rozpoczęcia transakcji.
- Analiza czasów oczekiwania: Istotną cechą zakładki historii blokad jest możliwość pokazania czasu, przez jaki sesje czekały z powodu blokad przez aplikacje. Jest to szczególnie przydatne do identyfikacji sesji, które powodują znaczne opóźnienia, zapewniając jasne cele do dalszego badania lub natychmiastowego działania.
Analiza sesji
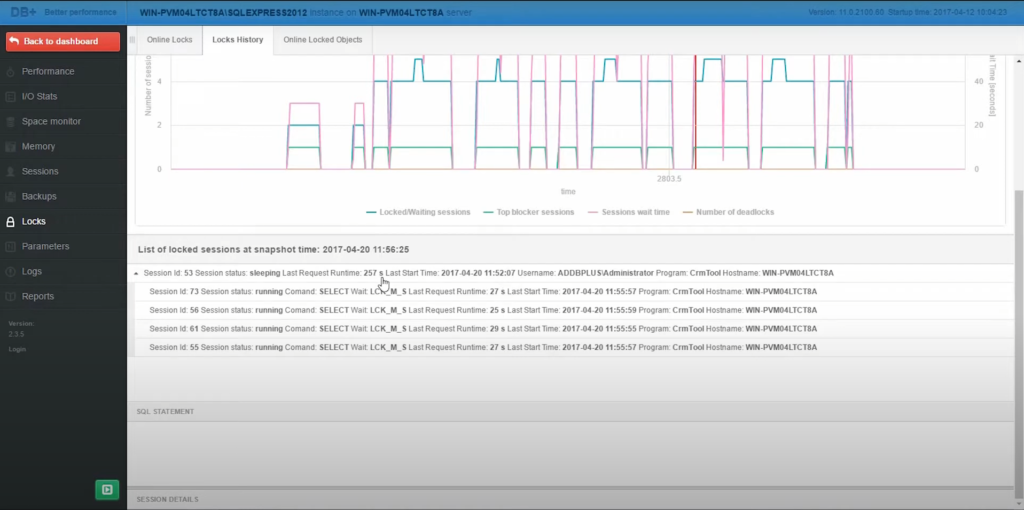
Sesja, o której mowa, była konsekwentnie oznaczana jako „uśpiona” w wielu snapshotach. Status ten wskazuje, że podczas gdy sesja była połączona i transakcja została zainicjowana, żadne aktywne zapytania nie były wykonywane przez dłuższy czas. Sesja rozpoczęła transakcję o godzinie 11:55, ale nie wykazała żadnej aktywności przez 257 sekund w początkowej obserwacji. Kolejne snapshoty wskazywały, że ta bezczynność trwała nadal, a sesja nadal nie wykonywała żadnych zapytań. Ta przedłużająca się bezczynność wstrzymywała zasoby, blokując jednocześnie inne transakcje, co prowadziło do wydłużenia czasu oczekiwania dla innych sesji.
Analiza przyczyn źródłowych
Analiza wykazała, że aplikacja użytkownika nie zarządzała odpowiednio swoimi transakcjami. Stan uśpienia transakcji wskazywał, że została ona zainicjowana, ale nie była aktywnie przetwarzana z powodu braku wykonywanych zapytań lub braku poleceń finalizacji transakcji, takich jak zatwierdzenie lub wycofanie. To niewłaściwe zarządzanie transakcjami sugeruje, że aplikacja może nie mieć solidnej obsługi błędów lub zasad limitu czasu transakcji, które mogłyby zapobiegać przedłużającej się bezczynności.
Wpływ na system
Niewłaściwa obsługa transakcji może prowadzić do kilku problemów w środowisku bazy danych, głównie poprzez tworzenie niezwolnionych blokad. W omawianym przypadku brak prawidłowego zarządzania stanami transakcji przez aplikację skutkował niepotrzebnymi blokadami przez aplikację na zasobach, które nie były aktywnie wykorzystywane. Powodowało to blokowanie innych transakcji i pogarszało ogólną wydajność systemu. Sytuacja ta pogarszała się w okresach największego obciążenia, gdy efekt kumulacji wielu nieefektywnych transakcji spowalniał działanie systemu.
Jak sobie z tym poradzić?
Jest wiele do zrobienia, aby zapobiec takim sytuacjom w przyszłości:
- Wdrożenie optymalizacji zapytań: Przejrzyj i zoptymalizuj wolno działające zapytania. Użyj strategii indeksowania i zoptymalizuj zapytania SQL, tak aby skrócić czas wykonywania i blokowania zasobów.
- Dostosowanie ustawień limitu czasu blokady: Ustaw odpowiednie ustawienia limitu czasu dla transakcji, aby zapobiec długim czasom oczekiwania. Może to pomóc w automatycznym zakończeniu transakcji, które powodują blokady, jeśli przekroczą określony próg czasowy.
- Wprowadzenie równoważenia obciążenia: Rozłożenie obciążenia bazy danych na wiele serwerów lub instancji. Pomoże to złagodzić wpływ ciężkich zapytań i ograniczyć występowanie blokad w godzinach szczytu.
- Mechanizmy kontroli współbieżności: Wdrożenie zaawansowanych mechanizmów kontroli współbieżności. Rozwiązania takie jak optymistyczna współbieżność lub wersjonowanie wierszy pomagają zarządzać spójnością danych bez konieczności stosowania dużych blokad.
- Regularne monitorowanie wydajności: Częściej korzystaj z narzędzi do monitorowania takich jak DBPLUS PERFORMANCE MONITOR. Są one niezbędne do wczesnego identyfikowania wąskich gardeł wydajności i podejmowania proaktywnych działań, zanim wpłyną one na wydajność systemu.


